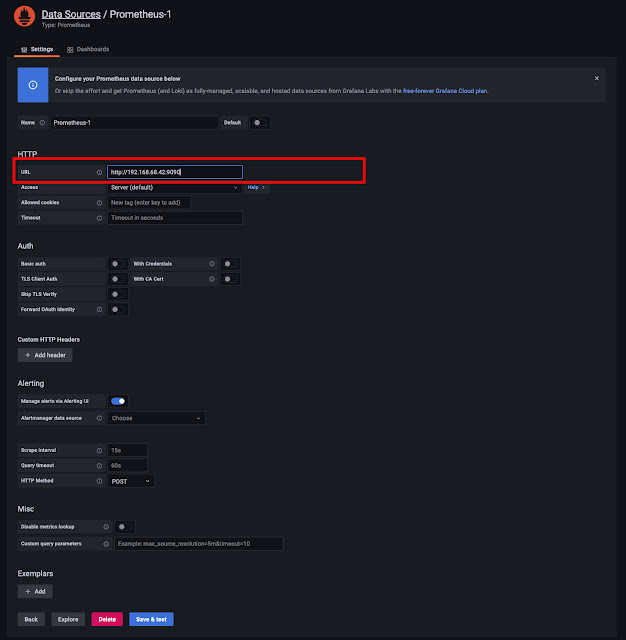
ヘルスチェック(HTTPポート指定:デフォルト値)でコケまくるので
TCPに変更
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "5"
creationTimestamp: "2024-08-17T05:57:02Z"
generation: 11
labels:
k8s-app: kube-dns
name: coredns
namespace: kube-system
resourceVersion: "186676"
uid: 37448d7a-0b91-42b5-9a55-bf2dfe2981d1
spec:
progressDeadlineSeconds: 600
replicas: 2
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kube-dns
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
annotations:
kubectl.kubernetes.io/restartedAt: "2024-12-06T10:48:09+09:00"
creationTimestamp: null
labels:
k8s-app: kube-dns
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- kube-dns
topologyKey: kubernetes.io/hostname
weight: 100
containers:
- args:
- -conf
- /etc/coredns/Corefile
image: registry.k8s.io/coredns/coredns:v1.11.1
imagePullPolicy: IfNotPresent
livenessProbe:
tcpSocket:
port: 53
initialDelaySeconds: 60
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 5
name: coredns
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153
name: metrics
protocol: TCP
readinessProbe:
tcpSocket:
port: 53
initialDelaySeconds: 0
timeoutSeconds: 1
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
resources:
limits:
memory: 170Mi
requests:
cpu: 100m
memory: 70Mi
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
drop:
- ALL
readOnlyRootFilesystem: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /etc/coredns
name: config-volume
readOnly: true
dnsPolicy: Default
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: coredns
serviceAccountName: coredns
terminationGracePeriodSeconds: 30
tolerations:
- key: CriticalAddonsOnly
operator: Exists
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane
volumes:
- configMap:
defaultMode: 420
items:
- key: Corefile
path: Corefile
name: coredns
name: config-volume
以下、コマンド実行してcoreDNSを再作成実施
kubectl rollout restart deployment coredns -n kube-system
以下実施後、権限エラーがでた
kubectl logs -n kube-system -l k8s-app=kube-dns
-------log---------
[ERROR] plugin/kubernetes: pkg/mod/k8s.io/client-go@v0.27.4/tools/cache/reflector.go:231: Failed to watch *v1.Service: failed to list *v1.Service: services is forbidden: User "system:serviceaccount:kube-system:default" cannot list resource "services" in API group "" at the cluster scope
------------------------------
RBACの追加を行う
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: coredns-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "namespaces"]
verbs: ["list", "watch"]
- apiGroups: ["discovery.k8s.io"]
resources: ["endpointslices"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: coredns-role-binding
subjects:
- kind: ServiceAccount
name: default
namespace: kube-system
roleRef:
kind: ClusterRole
name: coredns-role
apiGroup: rbac.authorization.k8s.io
テスト用にcoreDNSにサイドカーコンテナを追加して、nslookupを実施する
->疎通確認ができた。
apiVersion: apps/v1
kind: Deployment
metadata:
name: coredns
namespace: kube-system
spec:
replicas: 2
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
spec:
containers:
- name: coredns
image: registry.k8s.io/coredns/coredns:v1.11.1
args:
- -conf
- /etc/coredns/Corefile
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153
name: metrics
protocol: TCP
volumeMounts:
- mountPath: /etc/coredns
name: config-volume
readOnly: true
- name: busybox
image: busybox
command: ["sleep", "3600"] # これにより、コンテナが長時間実行されます
volumes:
- name: config-volume
configMap:
name: coredns
items:
- key: Corefile
path: Corefile